Question:
Why did the man in white hold tightly to the boy in white?
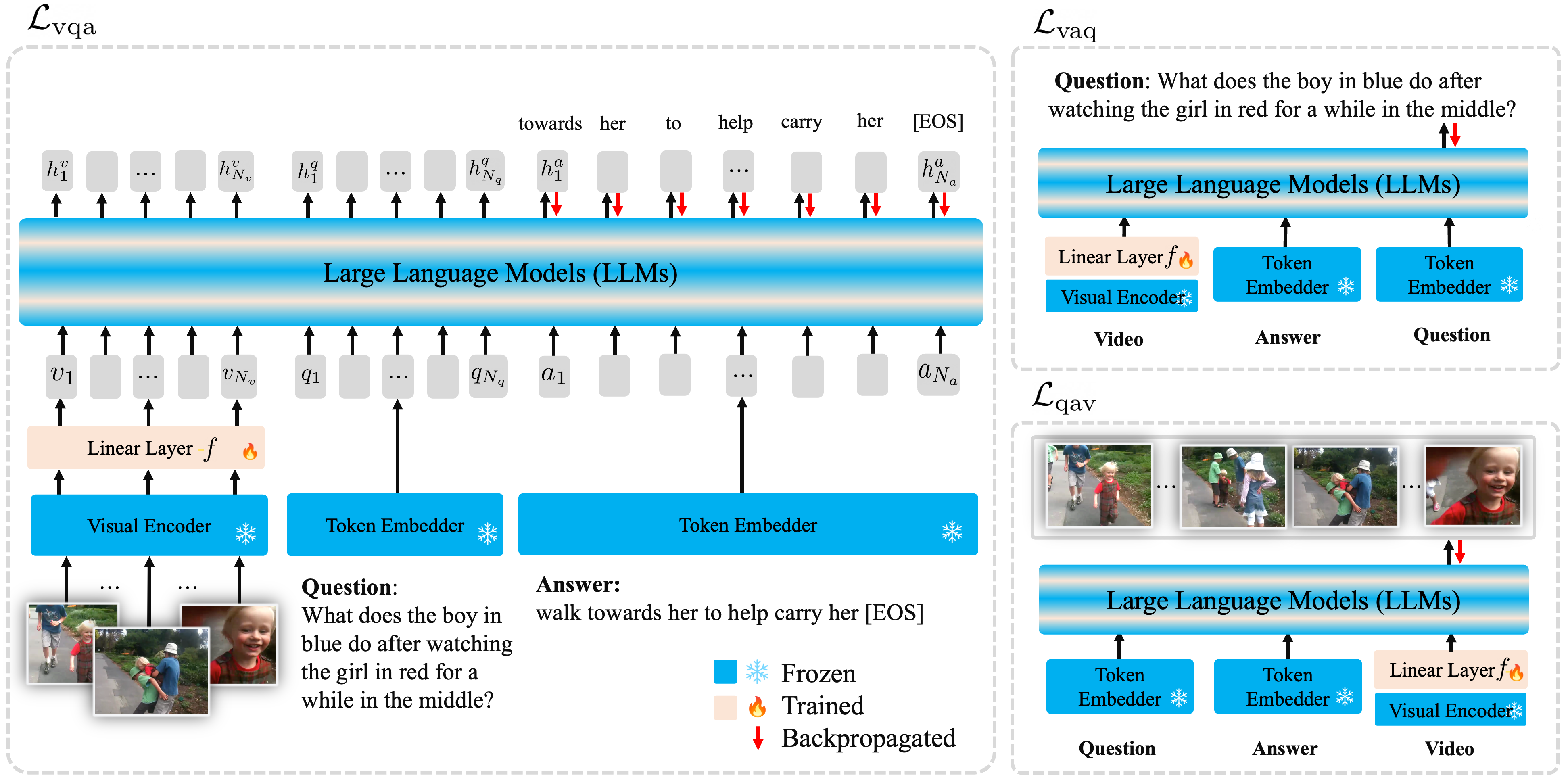
Large Language Models (LLMs) have shown remarkable performances on a wide range of natural language understanding and generation tasks. We observe that the LLMs provide effective priors in exploiting linguistic shortcuts for temporal and causal reasoning in Video Question Answering (VideoQA). However, such priors often cause suboptimal results on VideoQA by leading the model to overrely on questions, i.e., linguistic bias, while ignoring visual content. This is also known as 'ungrounded guesses' or 'hallucinations'. To address this problem while leveraging LLMs’ prior on VideoQA, we propose a novel framework, Flipped-VQA, encouraging the model to predict all the combinations of ⟨V, Q, A⟩ triplet by flipping the source pair and the target label to understand their complex relationships, i.e., predict A, Q, and V given a VQ, VA, and QA pairs, respectively. In this paper, we develop LLaMA-VQA by applying Flipped-VQA to LLaMA, and it outperforms both LLMs-based and non-LLMs-based models on five challenging VideoQA benchmarks. Furthermore, our Flipped-VQA is a general framework that is applicable to various LLMs (OPT and GPT-J) and consistently improves their performances. We empirically demonstrate that Flipped-VQA not only enhances the exploitation of linguistic shortcuts but also mitigates the linguistic bias, which causes incorrect answers over-relying on the question. Code is available at https://github.com/mlvlab/Flipped-VQA.
Try to answer the question given choices without referring to the video.
Why did the man in white hold tightly to the boy in white?
What did the lady do after she closed the box in front of her at the beginning of the video?
Our LLaMA-VQA model is effective in exploiting linguistic shortcut where the linguistic prior is correct (QA model already predicts the right answer soley based on question and choices without referring to the video).
Why are there lines everywhere on the ground?
What did the lady in black do after the baby picked up the towel?
Our LLaMA-VQA model is also effective in alleviating linguistic bias where the linguistic prior is incorrect (LLaMA-VQA corrects the answer by rejecting wrong linguistic prior, a plausible-sounding answer based on the common knowledge).
@inproceedings{ko2023large,
title = {Large Language Models are Temporal and Causal Reasoners for Video Question Answering},
author = {Dohwan Ko and Ji Soo Lee and Wooyoung Kang and Byungseok Roh and Hyunwoo J. Kim},
booktitle = {EMNLP},
year = {2023}
}