
Publications
International Conference Publications
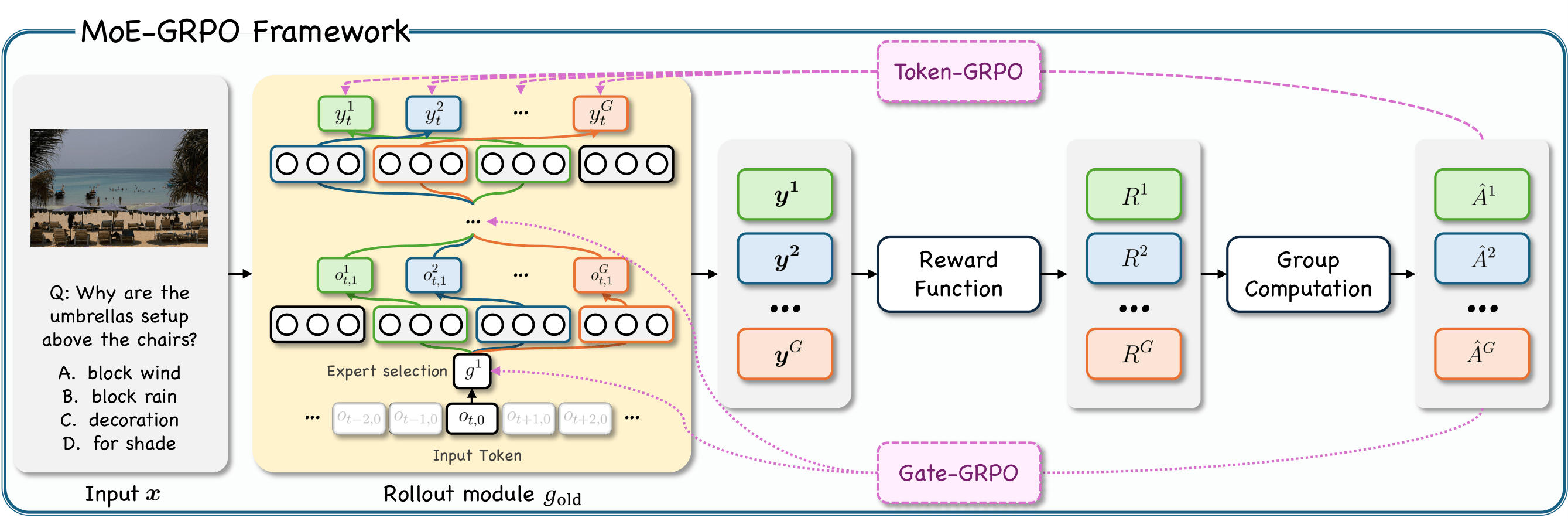
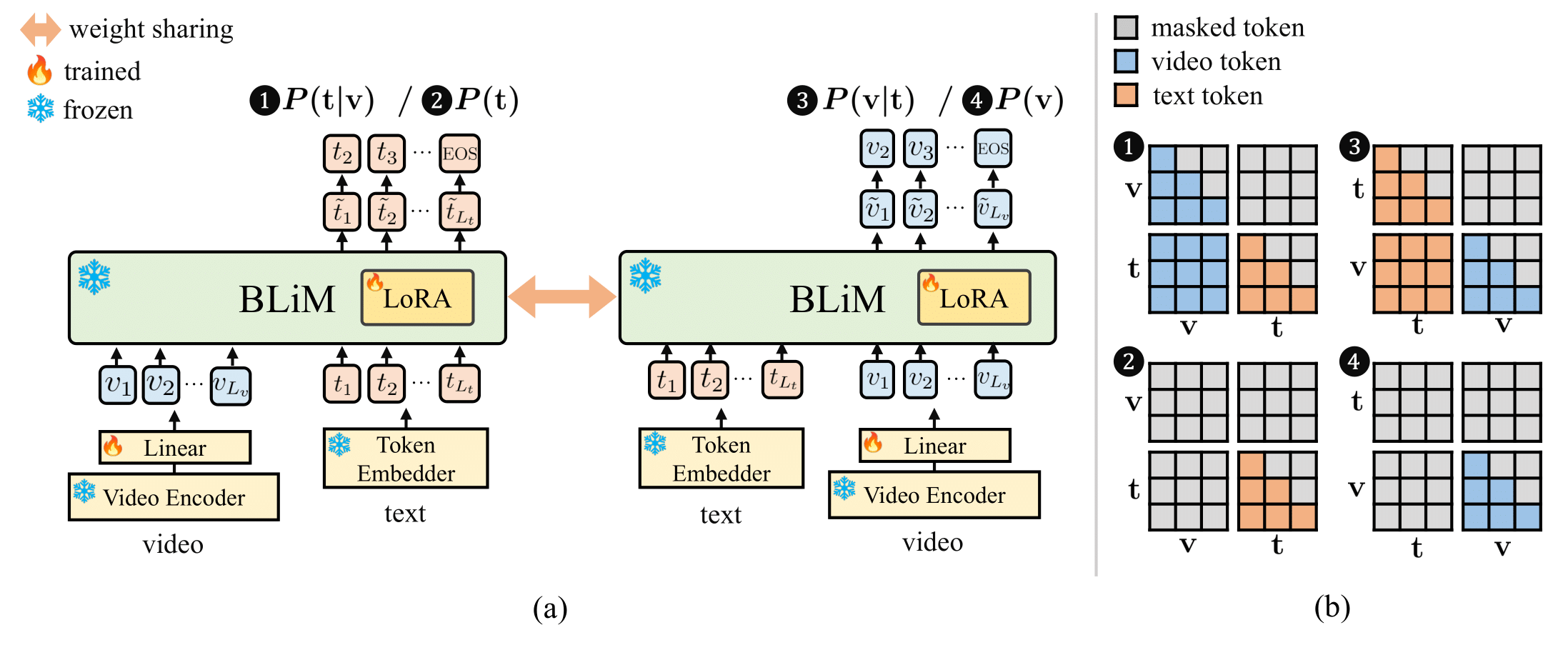
Bidirectional Likelihood Estimation with Multi-Modal Large Language Models for Text-Video Retrieval
Dohwan Ko*, Ji Soo Lee*, Minhyuk Choi, Zihang Meng, Hyunwoo J. Kim
Dohwan Ko*, Ji Soo Lee*, Minhyuk Choi, Zihang Meng, Hyunwoo J. Kim
ICCV 2025 Highlight (top 9.7%)
@inproceedings{ko2025bidirectional,
title={Bidirectional Likelihood Estimation with Multi-Modal Large Language Models for Text-Video Retrieval},
author={Ko, Dohwan and Lee, Ji Soo and Choi, Minhyuk and Meng, Zihang and Kim, Hyunwoo J},
booktitle={ICCV},
year={2025}}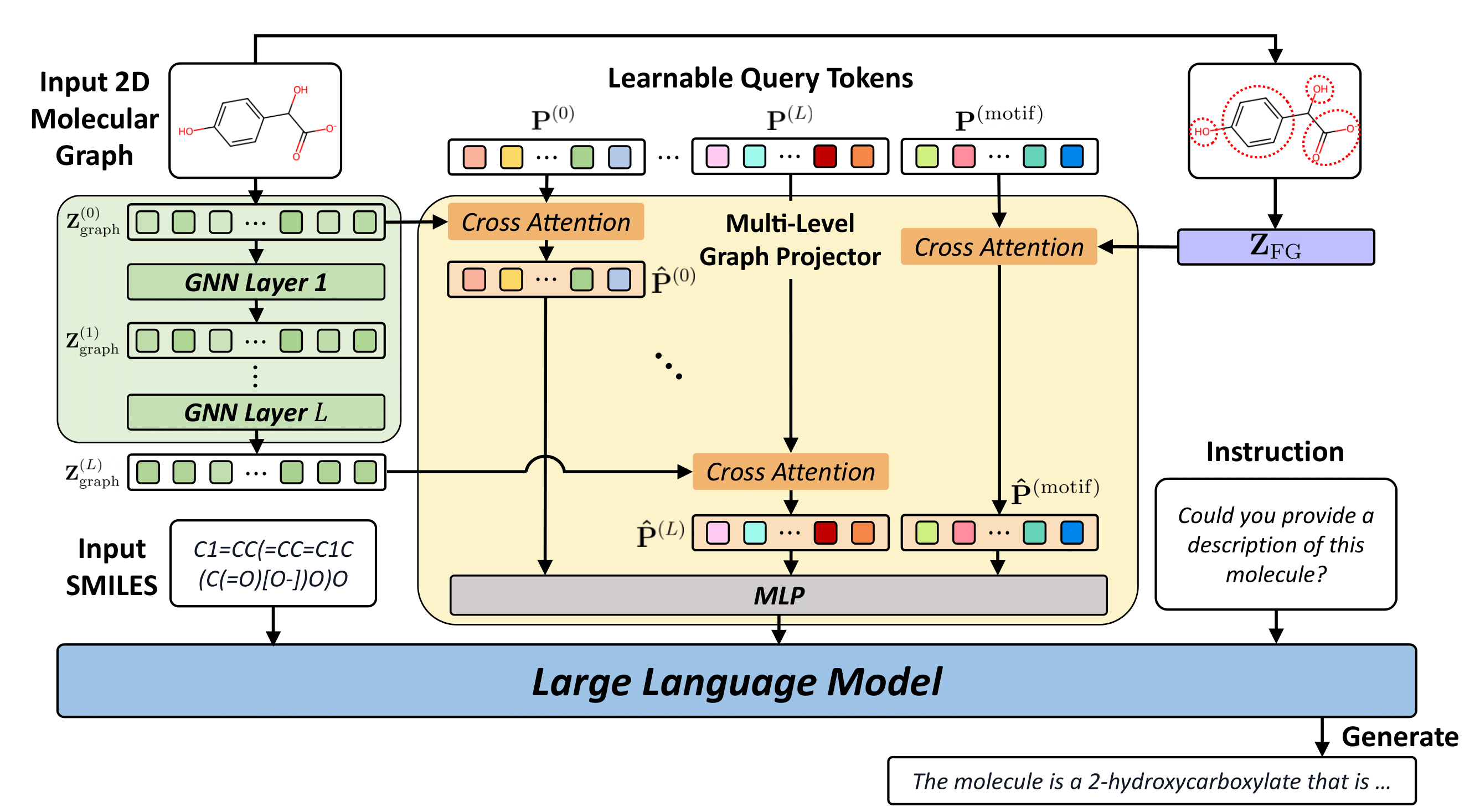
LLaMo: Large Language Model-based Molecular Graph Assistant
Jinyoung Park, Minseong Bae, Dohwan Ko, Hyunwoo J. Kim
Jinyoung Park, Minseong Bae, Dohwan Ko, Hyunwoo J. Kim
NeurIPS 2024
@inproceedings{park2024llamo,
title={LLaMo: Large Language Model-based Molecular Graph Assistant},
author={Park, Jinyoung and Bae, Minseong and Ko, Dohwan and Kim, Hyunwoo J},
booktitle={NeurIPS},
year={2024}}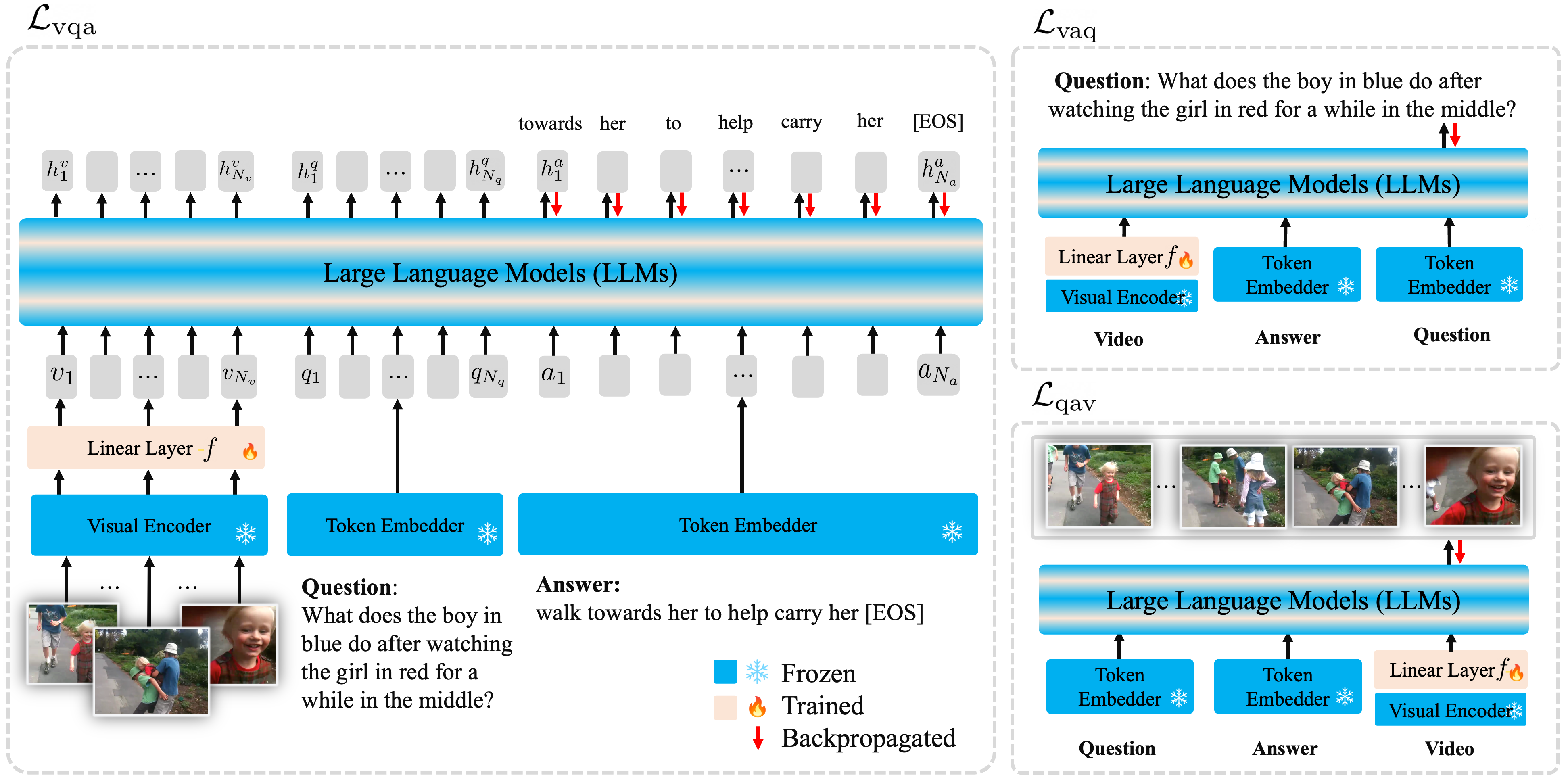
Large Language Models are Temporal and Causal Reasoners for Video Question Answering
Dohwan Ko*, Ji Soo Lee*, Wooyoung Kang, Byungseok Roh, Hyunwoo J. Kim
Dohwan Ko*, Ji Soo Lee*, Wooyoung Kang, Byungseok Roh, Hyunwoo J. Kim
EMNLP 2023 Main
@inproceedings{ko2023large,
title={Large Language Models are Temporal and Causal Reasoners for Video Question Answering},
author={Dohwan Ko and Ji Soo Lee and Wooyoung Kang and Byungseok Roh and Hyunwoo J. Kim},
booktitle={EMNLP},
year={2023}}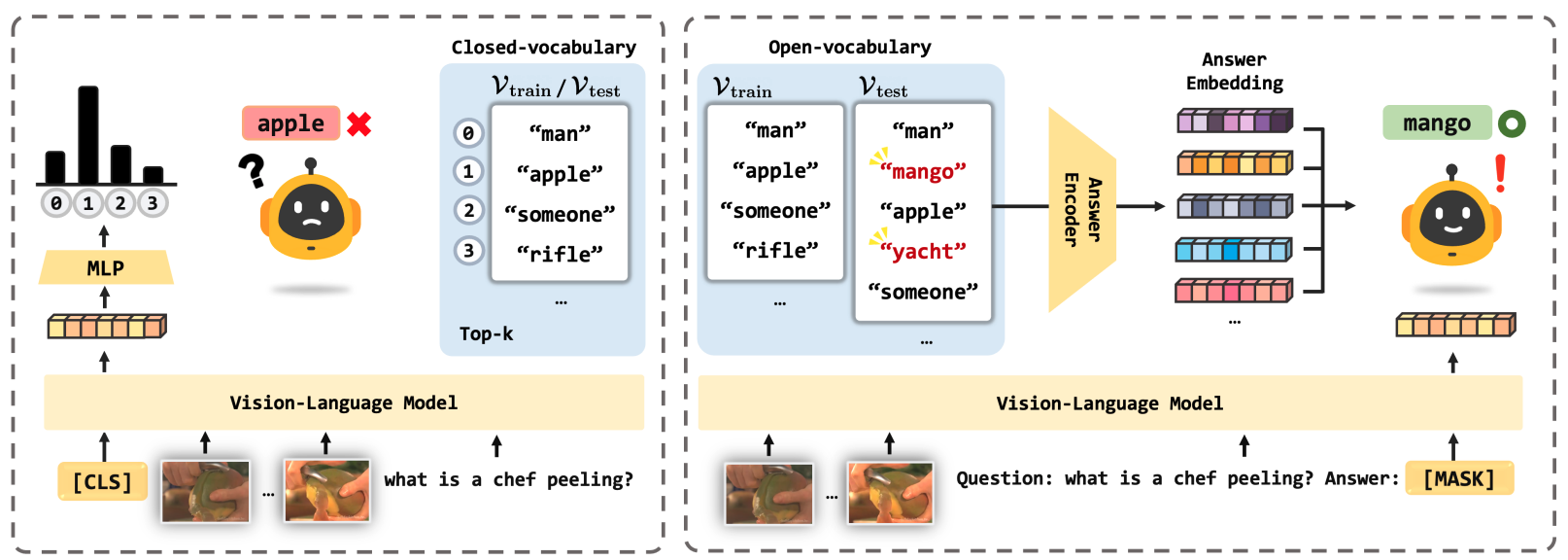
Open-Vocabulary Video Question Answering: A New Benchmark for Evaluating the Generalizability of Video Question Answering Models
Dohwan Ko, Ji Soo Lee, Miso Choi, Jaewon Chu, Jihwan Park, Hyunwoo J. Kim
Dohwan Ko, Ji Soo Lee, Miso Choi, Jaewon Chu, Jihwan Park, Hyunwoo J. Kim
ICCV 2023
@inproceedings{ko2023open,
title={Open-vocabulary Video Question Answering: A New Benchmark for Evaluating the Generalizability of Video Question Answering Models},
author={Ko, Dohwan and Lee, Ji Soo and Choi, Miso and Chu, Jaewon and Park, Jihwan and Kim, Hyunwoo J},
booktitle={ICCV},
year={2023}}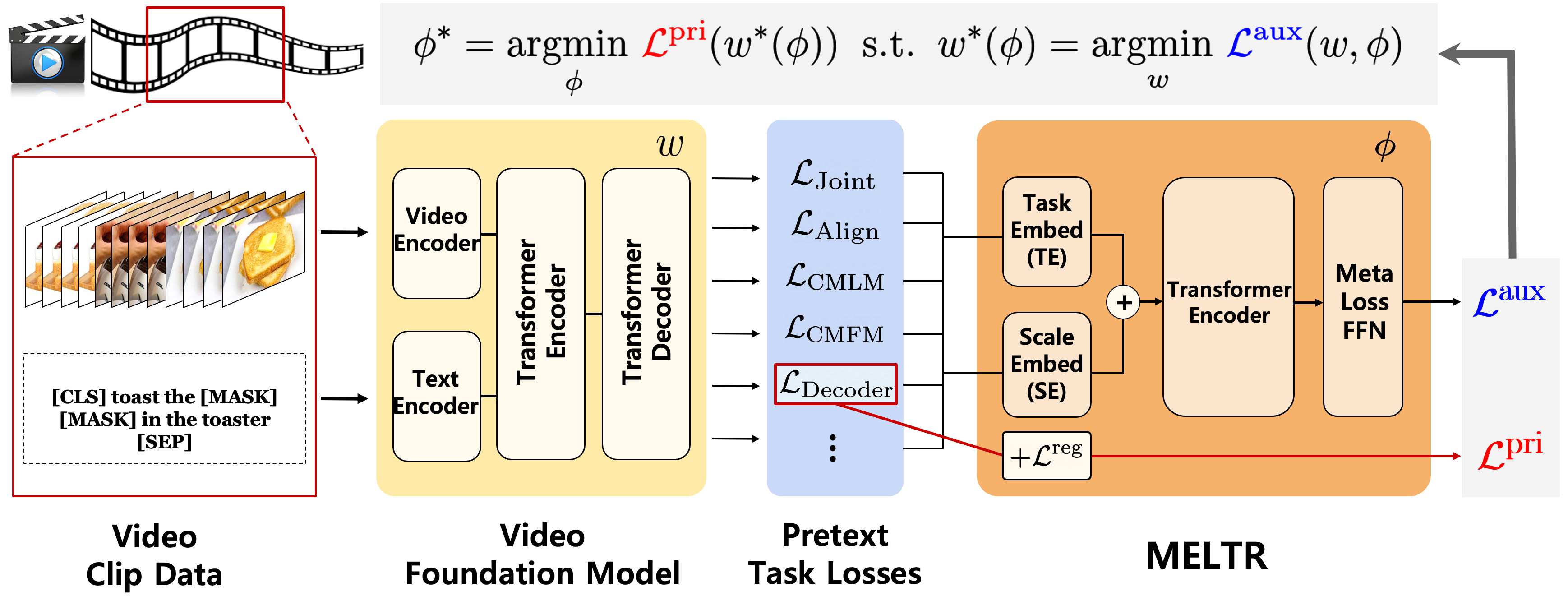
MELTR: Meta Loss Transformer for Learning to Fine-tune Video Foundation Models
Dohwan Ko*, Joonmyung Choi*, Hyeong Kyu Choi, Kyoung-Woon On, Byungseok Roh, Hyunwoo J. Kim
Dohwan Ko*, Joonmyung Choi*, Hyeong Kyu Choi, Kyoung-Woon On, Byungseok Roh, Hyunwoo J. Kim
CVPR 2023
@inproceedings{ko2023melrt,
title={MELTR: Meta Loss Transformer for Learning to Fine-tune Video Foundation Models},
author={Ko, Dohwan and Choi, Joonmyung and Choi, Hyeong Kyu and On, Kyoung-Woon and Roh, Byungseok and Kim, Hyunwoo J},
booktitle={CVPR},
year={2023}}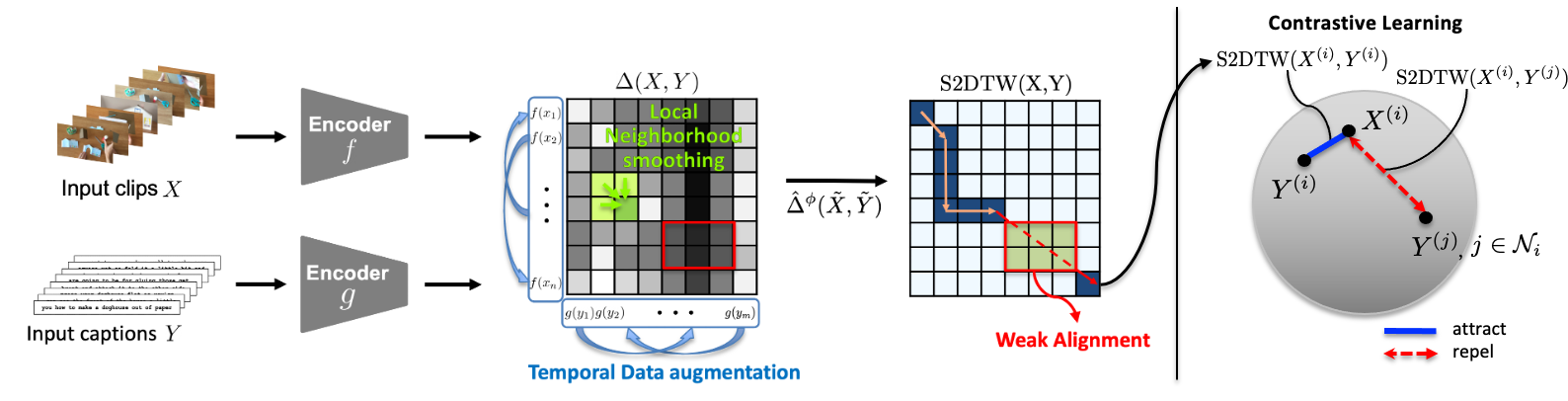
Video-Text Representation Learning via Differentiable Weak Temporal Alignment
Dohwan Ko, Joonmyung Choi, Juyeon Ko, Shinyeong Noh, Kyoung-Woon On, Eun-Sol Kim, Hyunwoo J. Kim
Dohwan Ko, Joonmyung Choi, Juyeon Ko, Shinyeong Noh, Kyoung-Woon On, Eun-Sol Kim, Hyunwoo J. Kim
CVPR 2022
@inproceedings{ko2022video,
title={Video-Text Representation Learning via Differentiable Weak Temporal Alignment},
author={Ko, Dohwan and Choi, Joonmyung and Ko, Juyeon and Noh, Shinyeong and On, Kyoung-Woon and Kim, Eun-Sol and Kim, Hyunwoo J},
booktitle={CVPR},
year={2022}}International Journal Publications
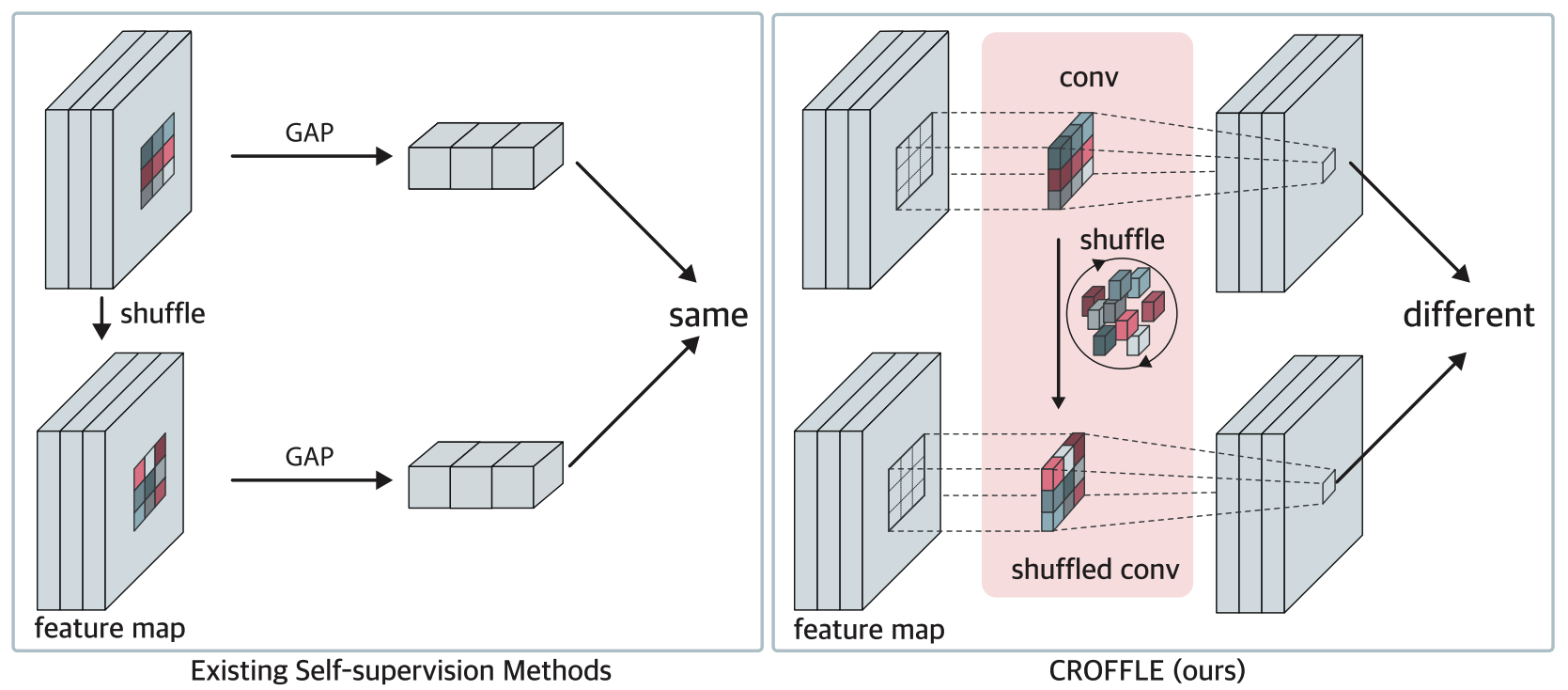
Randomly Shuffled Convolution for Self-Supervised Representation Learning
Youngjin Oh*, Minkyu Jeon*, Dohwan Ko, Hyunwoo J. Kim
Youngjin Oh*, Minkyu Jeon*, Dohwan Ko, Hyunwoo J. Kim
Information Sciences 2023
@article{oh2023randomly,
title={Randomly shuffled convolution for self-supervised representation learning},
author={Oh, Youngjin and Jeon, Minkyu and Ko, Dohwan and Kim, Hyunwoo J},
journal={Information Sciences},
year={2023}}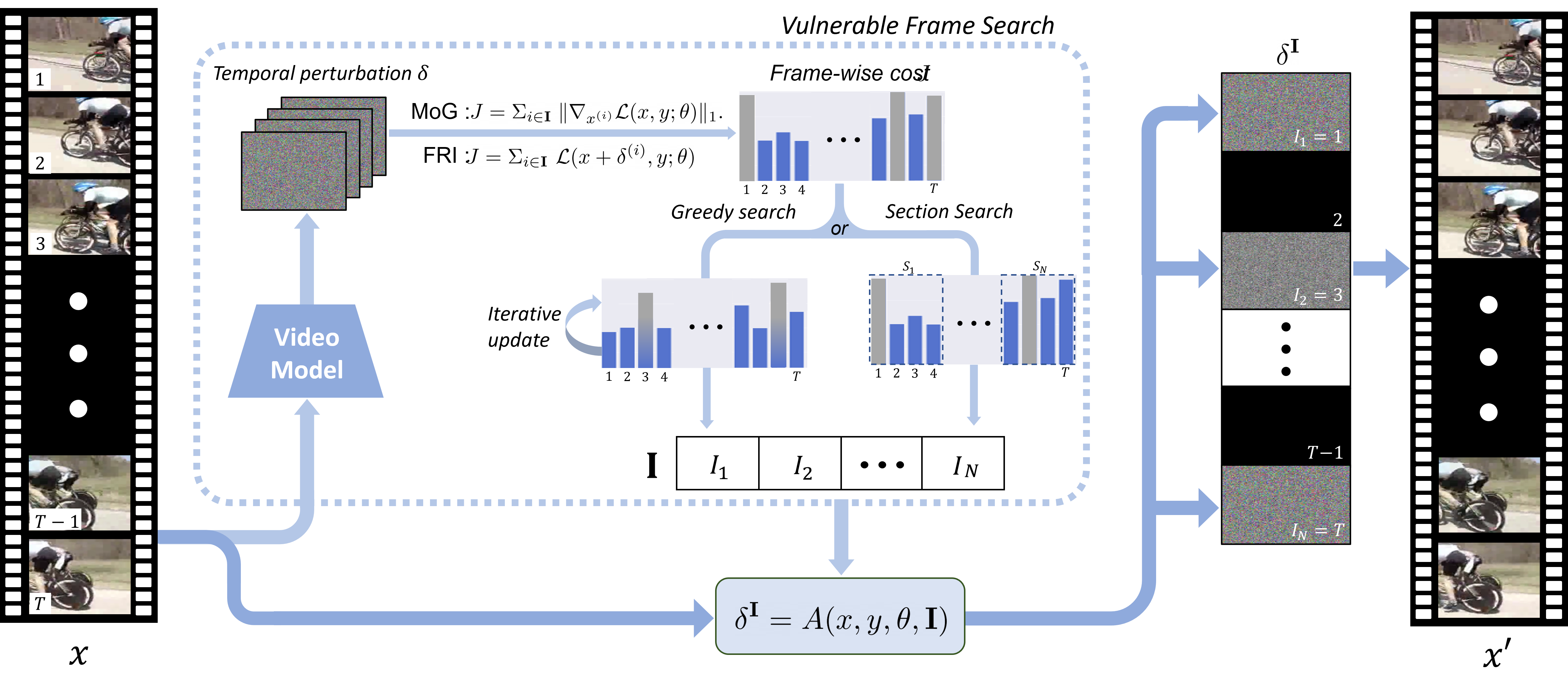
Search-and-Attack: Temporally SparseAdversarial Perturbations on Videos
Hwan Heo*, Dohwan Ko*, Jaewon Lee*, Youngjoon Hong, Hyunwoo J. Kim
Hwan Heo*, Dohwan Ko*, Jaewon Lee*, Youngjoon Hong, Hyunwoo J. Kim
IEEE Access 2021
@article{heo2021search,
title={Search-and-attack: temporally sparse adversarial perturbations on videos},
author={Heo, Hwan and Ko, Dohwan and Lee, Jaewon and Hong, Youngjoon and Kim, Hyunwoo J},
journal={IEEE Access},
year={2021}}Preprints
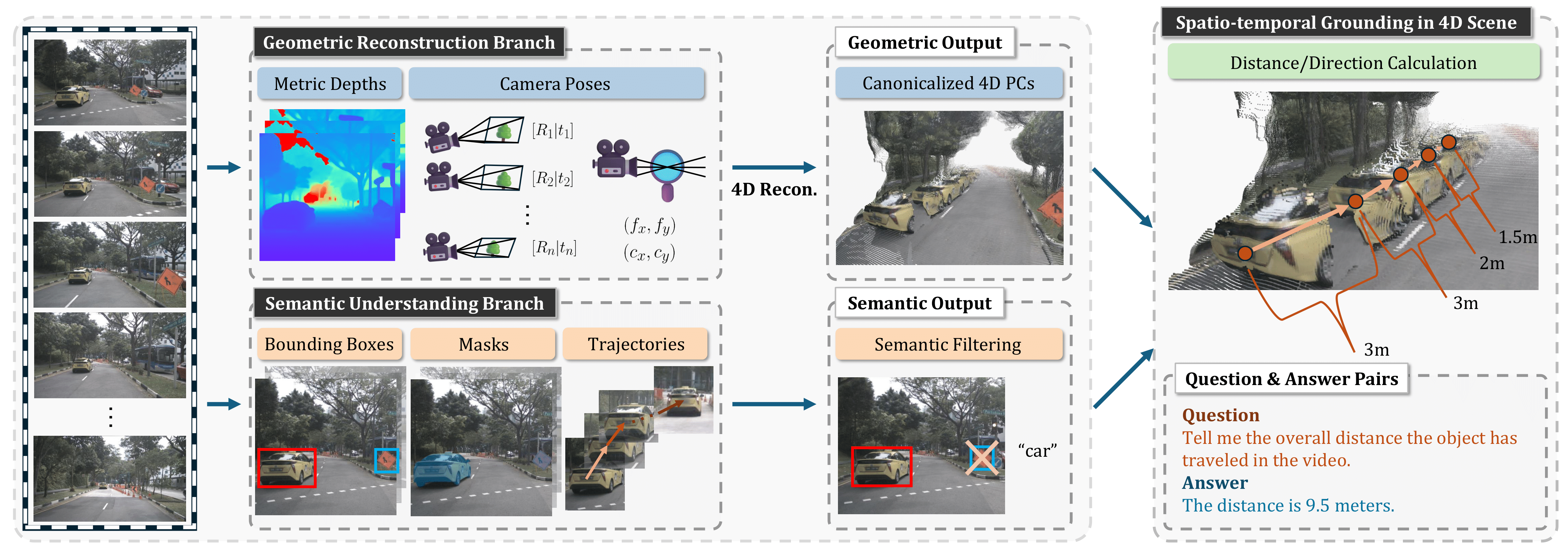
ST-VLM: Kinematic Instruction Tuning for Spatio-Temporal Reasoning in Vision-Language Models
Dohwan Ko*, Sihyeon Kim*, Yumin Suh, Vijay Kumar, Minseo Yoon, Manmohan Chandraker, Hyunwoo J. Kim
Dohwan Ko*, Sihyeon Kim*, Yumin Suh, Vijay Kumar, Minseo Yoon, Manmohan Chandraker, Hyunwoo J. Kim
arXiv preprint 2025
@article{ko2025st,
title={ST-VLM: Kinematic Instruction Tuning for Spatio-Temporal Reasoning in Vision-Language Models},
author={Ko, Dohwan and Kim, Sihyeon and Suh, Yumin and Yoon, Minseo and Chandraker, Manmohan and Kim, Hyunwoo J and others},
year={2025}}